Import data using the Command Line Interface (CLI)
Description
This chapter will show how to import data for another user, using Command Line Interface (CLI).
The import can be done by any user as long as they import the data for themselves.
In case of the import for others, the user importing the data needs to have some admin (or restricted-admin) privileges. More information about restricted privileges can be found at restricted-admins.
In the example workflow below, a user with restricted administrator privileges is used with login name importer1. This could be in real life e.g. a facility manager.
We will show:
How to import data using the CLI for myself and for others into a remote OMERO.server
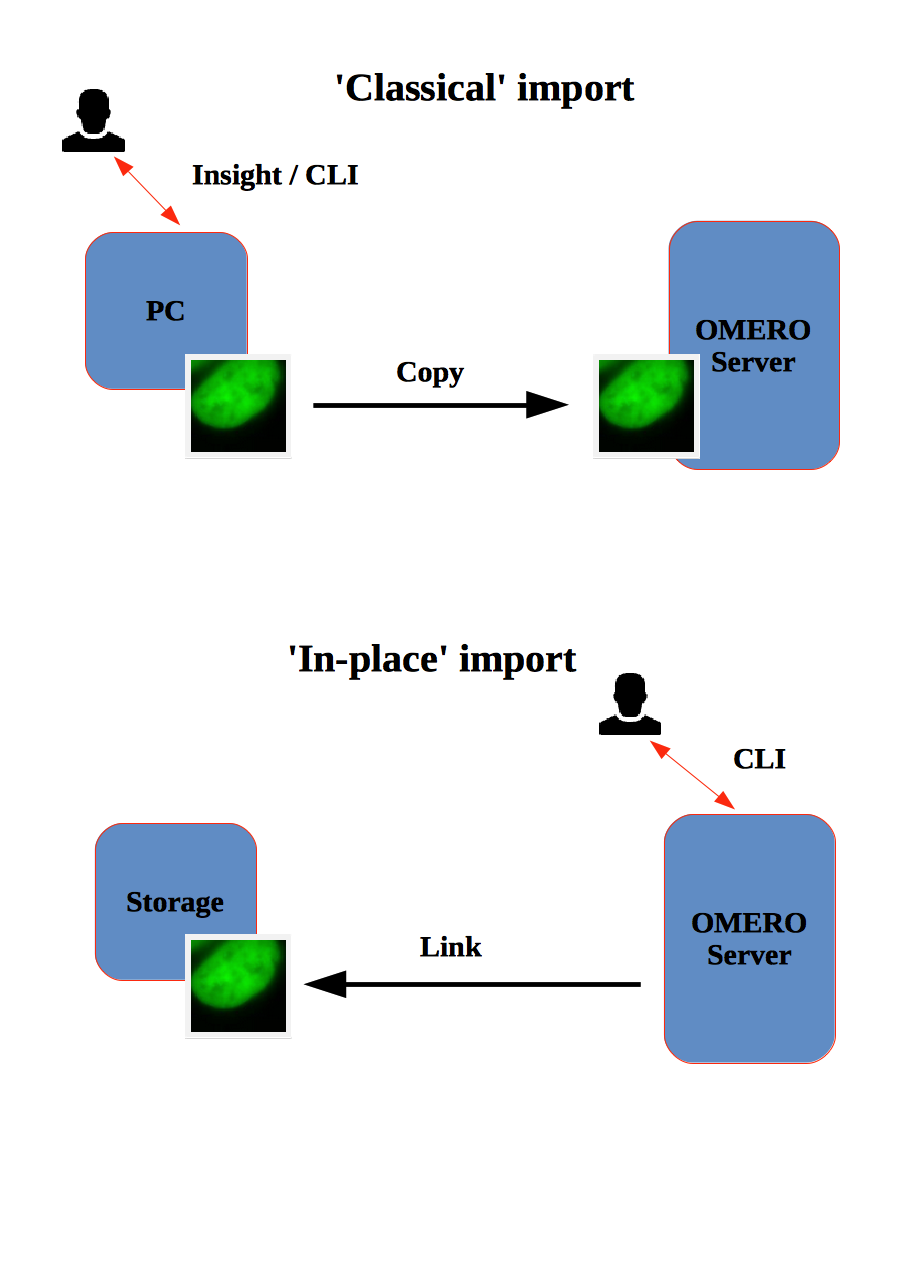
How to import data using the CLI “in-place”, which means not copying the imported data into OMERO. Instead, OMERO will point to the original location of “in-place” imported files, thus preventing data duplication.
How to deal with imports of large amounts of data in CLI, using the –bulk option and helper csv and yml files which define what is to be imported and how.
Resources
Documentation:
https://docs.openmicroscopy.org/latest/omero/users/cli/installation.html
https://docs.openmicroscopy.org/omero/latest/users/cli/index.html
https://docs.openmicroscopy.org/omero/latest/users/cli/import-target.html
https://docs.openmicroscopy.org/omero/latest/sysadmins/in-place-import.html
https://docs.openmicroscopy.org/omero/latest/users/cli/import-bulk.html
Data: example images from
Bash script for performing in-place imports:
Example files for bulk import
Setup
CLI Importer installation
Client libraries from the OMERO.server have to be installed on the client to import images using CLI.Please read the installation instructions.
Note: When importing for another user using the CLI, the importer1 does not have to be a member of the target group.
Step-by-step
If you did not do so already, open a terminal window on your local machine and activate the conda environment where your
omero-pyis installed (see the Setup section above):$ conda activate myenv
Set the
OMERODIRvariable to point to the downloaded and unzipped OMERO server dir (see the Setup section above):$ export OMERODIR=/path/to/OMERO.server-x.x.x-ice36-bxx
Login to the OMERO.server you wish to import to. This can be a remote OMERO.server. In the below example we log in as the user
importer1, who will import for themselves:$ omero -s your-server-address -u importer1 login
Go to the directory where there are some images you wish to import:
$ cd /path/to/images/directory/
Create an OMERO Dataset to import to:
$ DID=$(omero obj new Dataset name=import_for_myself)
Import the images as
importer1into the newly created Dataset. You can import a single image as in the example below, or a whole directory of images:$ omero import -d $DID <your-image-name>
Log in to OMERO.web as
importer1and verify the imported image in the newly created datasetimport_for_myself.Import an image for another user, for example
user-1. For that, yourimporter1user logs in asuser-1:$ omero --sudo importer1 -u user-1 login
Create a Dataset
import_for_user_oneasuser-1:$ DID=$(omero obj new Dataset name=import_for_user_one)
Import the data in the newly created Dataset:
$ omero import -d $DID <path-to-image-or-directory-with-images>
Check that the image(s) are successfully imported and that the image(s) and the containing Dataset both belong to
user-1(notimporter1).
In-place Import using the CLI
Instead of being copied into OMERO’s managed repository, the image files stay at their original place and are just linked into the repository.
It is only available for the CLI importer, using the argument --transfer=ln_s.
Advantages:
All in-place import scenarios provide non-copying benefit. Data that is too large to exist in multiple places, or which is accessed too frequently in its original form to be renamed, remains where it was originally acquired.
Limitations:
Only available on the OMERO server system itself.
Do not edit or move the files after an in-place import. OMERO may no longer be able to access them if you do.
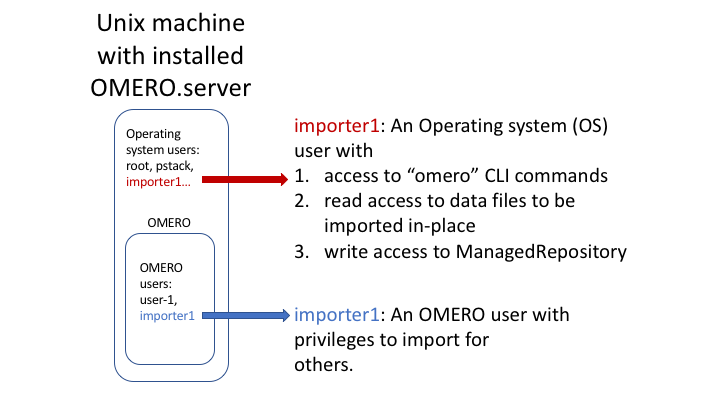
Important:
A user performing an in-place import MUST have:
a regular OMERO account
an OS-account with ability to run omero commands on server machine
read access to the location of the data
write access to the ManagedRepository or one of its subdirectories. Please check the ManagedRepository documentation.
Step-by-step:
Connect to the machine on which the OMERO.server is running as OS user
importer1usingssh.The aim is to import an image from
/OMERO/in-place-import/FRAP:$ ls /OMERO/in-place-import/FRAP
Activate the virtual environment where
omero-pyis installed or add it toPATH. In the example below, the path to the OMERO.server is/opt/omero/server:$ export PATH=/opt/omero/server/venv3/bin:$PATH
Point
OMERODIRto the location where the OMERO server is installed e.g.:$ export OMERODIR=/opt/omero/server/OMERO.server
Import now data for another user, this time a large image where the advantage of not copying the image file onto the server is most visible. The
importer1user logs in asuser-1:$ omero --sudo importer1 -u user-1 login
Create a Dataset
import_for_user_one:$ DID=$(omero obj new Dataset name=import_for_user_one)
‘In place’ import a large SVS file into the
import_for_user_onedataset:$ omero import -d $DID --transfer=ln_s /OMERO/in-place-import/svs/77917.svs
Check that the image is successfully imported.
Click on the paths icon
 to show the difference between the normal and in-place (ln_s) imported images. Validate that In-place import is indicated
to show the difference between the normal and in-place (ln_s) imported images. Validate that In-place import is indicated  .
.Note: The script in_place_import_as.sh shows how to perform the in-place import steps described above in one single command.
Bulk Import using the CLI
In this example, we show how to combine several import strategies using a configuration file. This is a strategy heavily used to import data to IDR.
We import two folders named siRNA-HeLa and condensation.
Note: Connecting over SSH is necessary only if you intend to import in-place. If you do not wish to perform the bulk import in “in-place” manner, you can connect to the server remotely using locally installed OMERO.cli and adjust the bulk.yml file by commenting out the transfer... line, then follow the steps as described below.
Open a terminal and connect to the server (for example as
importer1) overSSH. Alternatively, use your local terminal with installed OMERO.cli if not importing “in-place”.Description of the files used to set up the import (see
bulk.yml,import-paths.csvand import-bulk.html#bulk-imports for further details).import-paths.csv: (.csv, comma-separated values) this file has at least two columns. In this case the columns are separated by commas. The first column is the name of the target Dataset and the second one is the path to the folder to import. We will import two folders (theimport-paths.csvhas two rows).Example csv (note the comma between the “HeLa” and “/OMERO…”):
*Dataset:name:Experiment1-HeLa,/OMERO/in-place-import/siRNAi-HeLa**Dataset:name:Experiment2-condensation,/OMERO/in-place-import/condensation*bulk.yml: this file defines the various import options: transfer option, checksum algorithm, format of the .csv file, etc. Note that setting the dry_run option to true allows to first run an import in dry_run mode and copy the output to an external file. This is useful when running an import in parallel. Comment out thetransfer" "ln_s"if not importing “in-place”.Example bulk.yml:
*continue: "true"* *transfer: "ln_s"* *# exclude: "clientpath"* *checksum_algorithm: "File-Size-64"* *logprefix: "logs"* *output: "yaml"* *path: "import-paths.csv"* *columns:* - *target* - *path*
Activate the virtual environment where
omero-pyis installed or add it toPATH. In the example below, the path to the OMERO.server is/opt/omero/server:$ export PATH=/opt/omero/server/venv3/bin:$PATH
Point
OMERODIRto the location where the OMERO server is installed e.g.:$ export OMERODIR=/opt/omero/server/OMERO.server
Find the place where the
bulk.ymlfile is located, for example/OMERO/in-place-import:$ cd /OMERO/in-place-import
The
importer1(Facility Manager with ability to import for others) OMERO user logs in asuser-1:$ omero --sudo importer1 -u user-1 login
Import the data using the
--bulkcommand:$ omero import --bulk bulk.yml
Go to the webclient during the import process to show the newly created dataset. The new datasets in OMERO are named Experiment1-HeLa and Experiment2-condensation. This was specified in the first column of the
import-paths.csvfile.Select an image.
In the right-hand panel, select the General tab to validate:
Click on
to show the import details.Validate that In-place import is indicated
in case you imported “in-place”.
Advantages:
Large amount of data imported using one import command.
Heterogeneous data for multiple users can be imported using bulk import in combination with bash scripting, e.g. in_place_import_as.sh
Reproducible import.
Limitations:
Preparation of the .csv or .tsv file.
Combine the CLI imports with post-import steps
The following example shows how to do the import on CLI and follow-up operations like rendering and metadata import in one step.
In many cases, the rendering and metadata import is best done separately, as the visual checking of the imported images might be crucial for further rendering and metadata import, see Change image rendering settings and channel names using the Command Line Interface (CLI) and Import metadata using the Command Line Interface (CLI) for details on this.
Further, the images you are importing might need a range of different rendering settings, not just one set of settings for all of them. Also for this case, the step-by-step approach, first importing the images, only then deciding on the rendering strategy and preparing the renderingdef.yml files, is preferable.
Nevertheless, there are cases which do not need visual checks and use a single rendering for all images, for which a streamlined sequence of commands is offered below which will perform all three steps (import, rendering and metadata import) in one single session on the CLI.
Resources
Additionally to the Resources mentioned in the import-cli section and in the Setup you will also need the rendering and metadata plugins as mentioned in Change image rendering settings and channel names using the Command Line Interface (CLI) and Import metadata using the Command Line Interface (CLI), and possibly the following files:
Step-by-step
If you did not do so already, open a terminal window on your local machine and activate the conda environment where your
omero-pyis installed (see the Setup):$ conda activate myenv
Set the
OMERODIRvariable to point to the downloaded and unzipped OMERO server dir (see the Setup):$ export OMERODIR=/path/to/OMERO.server-x.x.x-ice36-bxx
Prepare an renderingdef.yml file, by either creating a new one or downloading https://raw.githubusercontent.com/ome/training-scripts/master/maintenance/preparation/renderingdef.yml.
Prepare an annotation.csv file, by creating a new file or downloading the provided example file. In the example below, we use the file
simple-annotation.csv. The Dataset names in this CSV file must match the Dataset names in OMERO as created in the DID variable definition line in the command below. The Image names in the CSV file must match the file names in your imported folder.Prepare a bulkmap-config.yml file. In the example below, we use the file
simple-annotation-bulkmap-config.yml.Log in to the OMERO.server you wish to import to. This can be a remote server if you do not wish to import in-place.
Import, render and annotate in a single command sequence below:
$ PID=$(omero obj new Project name='Project_import_concatenate') $ DID=$(omero obj new Dataset name='siRNAi-HeLa') $ omero obj new ProjectDatasetLink parent=$PID child=$DID $ omero import -d $DID /path/to/data/folder/or/image/siRNAi-HeLa --file import.out $ omero render set $DID renderingdef.yml $ omero metadata populate --report --batch 1000 --file /path/to/downloaded/simple-annotation.csv $PID $ omero metadata populate --context bulkmap --cfg simple-annotation-bulkmap-config.yml --batch 100 $PID
Log in to OMERO.web and check that the images are imported, have the expected rendering setttings and also the annotations in the form of Key-Value pairs on each imported image.
For more information about CLI import options, go to import.html.